
System Design for a Search Index
In Interview Camp’s Live Session, we discussed implementing a Search Index. This index consumes text documents, indexes them and lets users perform search queries. An example of such a system is Amazon ElasticSearch or Apache Lucene.
Caveat: We don’t want to go too deep into Information Retrieval, we want to cover only things that you can use in a general system design interview.
We will start off with a simple model, no distributed scaling, no complex queries.
We have Documents that need to be searchable. We want to put them in an index and perform simple search query – just one word queries. For each query, we will return the document that contains the word and how many times the word occurs in the doc.
For example:

Simple, right? This simple model helps us make a high level diagram for a search indexing system. That is a good starting point. Later on, we can make it more complicated.
At a high level, our system needs to consume a document, convert it into tokens, and store the tokens in a database. To search, our system will convert a query into tokens (in this case, our query is just one word) and then look up the tokens in the index database.
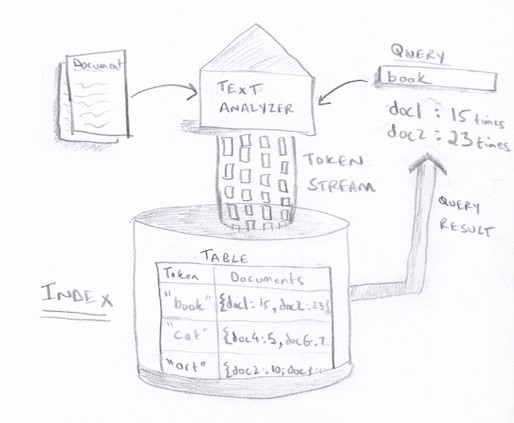
Chances are that the interviewer will want to focus on the Index and how to store and scale it. To implement the Index, you can use a distributed Wide-Column store such as HBase, which will scale well. For more information on their inner workings, please look at Interview Camp Lectures. We have explained in detail how these databases scale.
A unique part of this system is the Text Analyzer, which converts text into tokens. Although not common, the interviewer can ask you how to implement it. Keep in mind that they will not expect you to know details about NLP (unless that’s your background) – they will probably expect a high level implementation. Here are a few general points you can consider for your implementation:
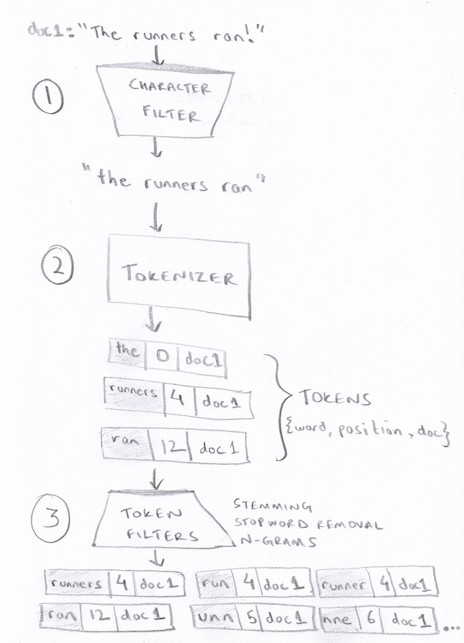
The analyzer needs to perform three steps for each document (or query) it receives:
- Character Filter – filter out unwanted characters (commas, semicolons, etc.), lowercase all letters
- Tokenizer – split the text into tokens (or words. Token is just a word with other info such as position, documentId, etc.)
- Token Filters – expand each token into related words. For example, “runners” to {“run”,”runner”,”runners”}
For Token Filtering, we can mention 2-3 common token filters without going into too much NLP specific detail:
- Stemming – reducing words to their base word, e.g, running -> run
- N-Grams – if partial text is searchable, add substrings of length N, e.g, 3-grams of “runner” are “run”, “unn”, “nne” & “ner”.
- Stop word removal – ignore words that are too common, e.g, “is”, “the”, “for”, etc.
You don’t need to go into details or know how these algorithms work. These are NLP specific algorithms.
Once you go through these 3 steps, you will have a decent list of tokens to feed to your index.
Now, let’s say we want to support multiple word queries. We will need to search for multiple tokens in our index, and then combine the output of those tokens. For example, let’s say we search for “run fast”. We will do a query for “run” and another one for “fast”. We will get two rows of documents. E.g,
“run”: {doc1: 15 times, doc2: 10 times, doc3: 5 times}
“fast”: {doc2: 10 times, doc3: 7 times, doc4: 11 times}
We will find documents that contain both the words, and return the intersection of the two rows:
{doc2, doc3}
This is not ideal, of course, but it is a simple search technique. doc2 and doc3 both have the two words. We probably need to return them in some order, with the first result being more relevant. We can use the number of times the words occurred, and total the counts. E.g.:
{doc2: 20, doc3: 12}
But that is not a very good metric to use for ranking. A better approach would be to calculate some sort of score about how relevant the word is to the document. Now, calculating this score is a little to complicated for most interviews, so you probably won’t need to go into more details. but if you are curious, you can look at TF-IDF which does exactly that.
We can store other things in our database depending on what we need. For example, if we need to output a text snippet of the search term in the document, we can use word positions stored in our tokens to extract the snippet from the document. For that, it could be efficient to store the document text separately in our database (something like cached pages in Google).
Caching Popular Queries
We also want to cache popular queries if our search needs to scale. It doesn’t make sense to query and combine results every time for common queries. We can use Memcached for that. We can run periodic jobs to batch process these queries and put them into Memcached.
App Servers
In a web backend, most of the processing logic is performed by App Servers. We need 3 types of App Servers in our system:
- Text/Token Analyzer: As shown above, consumes documents and queries and outputs a stream of tokens.
- Index Writer: Consumes the token stream from the Text Analyzer and updates the tables in the database. To make things faster, we should first write to an in-memory database such as Redis and then periodically flush the contents to the DB. This is because doing roundtrips from the DB for every token takes longer.
- Query Processor: Queries the index and processes the query.
The model above should fit into the System Design Anatomy we introduced in the lectures.
If you want to read more about Lucene, an open source search indexing system, you can look at the following paper:1