📹 Live: Scaling your Algorithms for Large Data - Part 2
In today's live session, we went over scaling an algorithm by using a distributed data processing system. We had several discussions around the following topics:
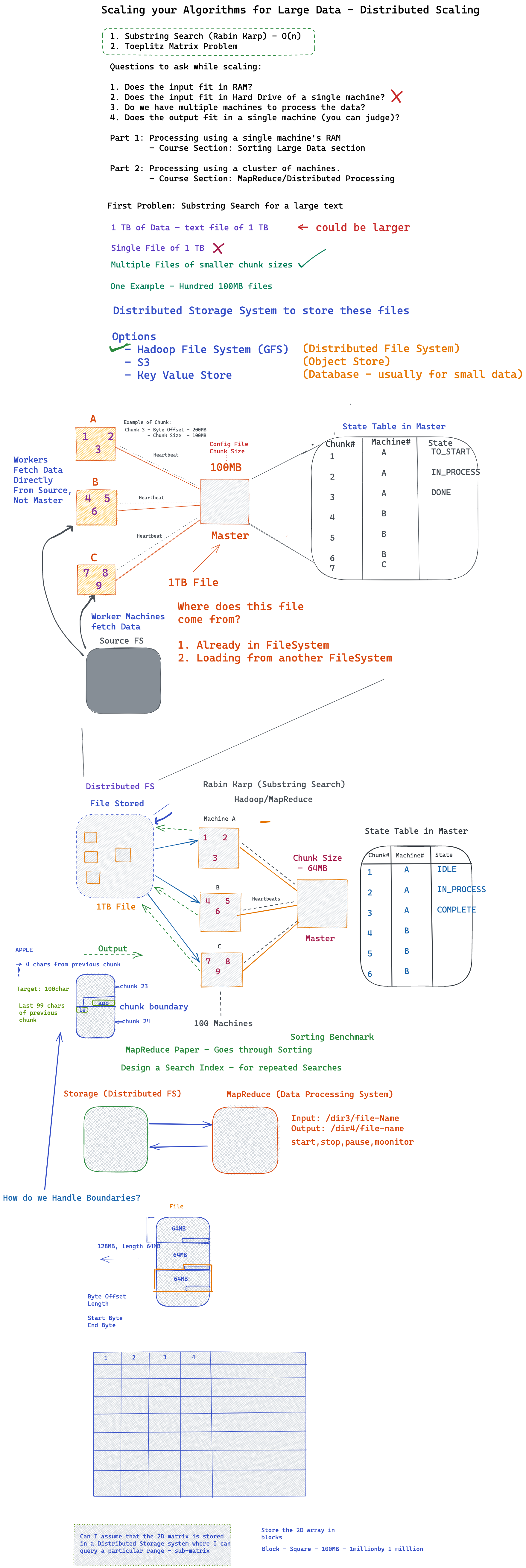
- What is the best way to set up a large input, for e.g, a 10 TB file?
- What is the best way to process the large file?
- What storage system to use?
- What distributed data processing system to use?
- How to tolerate faults in the system?
- How to manage the system - when to start, stop, and monitor the states of ongoing processes.
We designed a concrete system for processing a large file - we discussed doing String Search on the file using Rabin Karp Algorithm. We also discussed a problem that involved scaling a 2D matrix over multiple machines.
Notes are attached below. To attend these sessions live, please sign up for our trial at InterviewCamp.io